Nur ein Mensch weiß, ob ich diesen Post gerade schreibe: ich.
Vielleicht tue ich es ja. Vielleicht copy und paste ich in diesem Moment aber auch Versatzstücke von chat.openai.com rüber nach WordPress, nachdem der Prompt „Schreibe einen Blogpost über die Gefahren, die künstliche Intelligenz für Social Media darstellt.“ einen durchaus ansehnlichen Text generierte: Perspektive aus der ersten Person Singular, lockere Tonality, 12.000 Zeichen inklusive Leerzeichen, danke!
Doch warum ist es so schwer, menschlich erschaffenen Content (hier: ein Blogpost) von maschinellen Inhalten zu unterscheiden? Jahrzehnte der Filmgeschichte haben uns den Eindruck vermittelt, dass künstliche Intelligenz zwar unheimlich intelligent sein kann, ihre sprachliche Kapazität aber stets mindestens ebenso unheimlich ungelenk daherkommt: „Beep, Boop!“ – blechern und monoton, während silbensynchron irgendwo ein rotes Licht blinkt.
Im Unterricht bei Twitter
Der Grund, warum wir uns irrten? Gute Bildung! Generative KI-Modelle wie ChatGPT sind allesamt in sozialen Medien zur Schule gegangen. So zahlte OpenAI bis vor Kurzem Twitter Inc. noch Jahr für Jahr zwei Millionen US-Dollar, um das eigene Modell auf der Plattform in den Unterricht schicken zu dürfen. Hier lernte es durch das unermüdliche Studium von Tweets und Replys, die menschliche Sprache zu imitieren, aber auch den argumentativen Habitus zu simulieren. Trainingseinheiten für KIs gab und gibt es ebenso auf Facebook oder Instagram, Pinterest, in Subreddits, bei LinkedIn und auf Blogs. Vom natürlichen Satzbau bis zum Erschaffen täuschend echter Fotolandschaften steht alles auf dem Lehrplan. Die Resultate müssen nicht der Wahrheit entsprechen, sondern in erster Linie unseren Erwartungen. Sie müssen authentisch wirken.
Und das tun sie. Und so nehmen wir unseren Irrtum mit Begeisterung zu Kenntnis und kreieren nun täuschend echte Text- und Bildwelten, die wir mit anderen teilen, in Hausarbeiten, in E-Mails, in Konzepten und Plänen und auch immer häufiger auf Social Media. Die einen weniger, die anderen mehr – vor allem jene, die in der künstlichen Intelligenz keine reinen Co-Piloten oder Assistenten sehen, sondern lukrative Black Boxes, die neuerdings in der Lage sind, komplette Wertschöpfungsketten abzubilden.
Wenn im vergangenen Jahrzehnt der heiße Scheiß des passiven Einkommens aus Dropshipping bestand, so lässt sich heute eine Kombination weniger KI-Dienste zur rentablen Cash Cow formen. Noch während ChatGPT die Erzählung schreibt, macht sich Midjourney schon an die Erschaffung korrespondierender Illustrationen. Nach drei Klicks wandert das Ergebnis zu Amazon KPD, von wo aus nach wenigen Stunden eine Kindle-Bildergeschichte in die weltweiten Amazon-Marktplätze geschossen wird, um fortan rund um die Uhr Einkommen zu generieren; für einen Autor, der weder schreiben noch zeichnen kann. Und das gilt für 2023. Innerhalb der kommenden fünf Jahre lässt sich das Geschäftsmodell mit Sicherheit auf künstlich generierte Filme erweitern.
Eine Flut maschinell generierten Materials
Auch bei der Bewerbung per SEO oder Social Media kommt künstliche Intelligenz zum Einsatz. Die Zahl der YouTube-Tutorials und Blogposts, die sich mit dem Themenkomplex KI und Online-Marketing beschäftigen, explodiert jeden Tag aufs Neue: KI für Content-Ideen, KI für Posting-Texte, KI für Keywords, KI für Zielgruppendefinitionen, KI für Engagement, KI für Hashtags, KI für Teaser-Bilder, KI für Umfragen, KI für Support, KI für Sentiment-Analysen, KI für Tonality-Tweaks. Die Anwendung der Technologie wird immer einfacher, was mitunter an ihren einladenden WYSIWYG-Interfaces liegt, die für jeden zu meistern sind, der per Keyboard einen Satz tippen kann. Tausende Fragen, die etwa das Urheberrecht betreffen oder die Echtheit der Informationen, sind bis heute unbeantwortet – dennoch (oder gerade deshalb) stehen wir so kurz davor, den Autopilot-Button für die gesamte Kommunikation im Netz zu finden. So kurz!
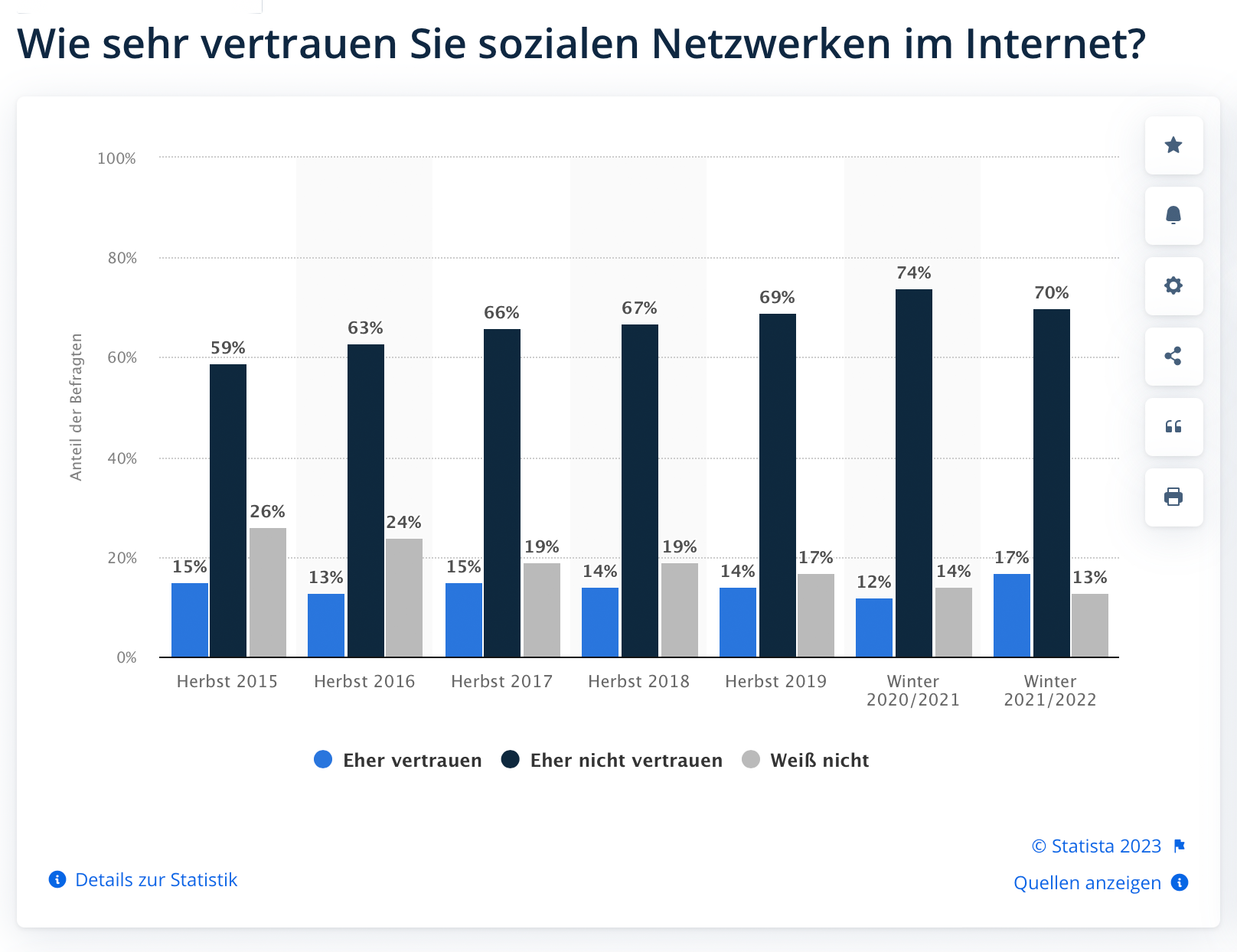
Die Folge ist eine dröhnende Flut maschinell generierten Materials, die schon heute durch die Netzwerke spült. Tausende von Roboter-Accounts, die Terabytes künstlicher Texte und Bilder in die Timelines der Nutzer drücken – ohne Kennzeichnung, ohne Signatur oder andere Hinweise, die auf die Urheberschaft schließen lassen. Das Vertrauen in die sozialen Netzwerke (s. Grafik unten) befindet sich nach einem Jahrzehnt gravierender Datenschutzverstöße, Hetze, Fake News, Shadowbanning und sensationsgesteuerter Visibility-Algorithmen bereits in einem Abwärtsstrudel. Der Siegesmarsch KI-generierter Inhalte wird wohl vollends eine Glaubwürdigkeitskrise auslösen: Fake-Accounts posten Fake-Bilder neben Fake-Teasertexten mit Fake-Aufrufen. Was ist ein legitimes Selfie? Was ist Deepfake? Ist die Audionachricht echt oder das Ergebnis intelligenter Text-to-Speech-Software? Wir beginnen, nicht nur maschinellem Content zu misstrauen, sondern auch die Erzeugnisse menschlicher Produktion zu hinterfragen.
Und so kann aus dem sozialen Raum schnell ein digitales Soliloquium werden, ein Selbstgespräch, das wir umgeben von artifiziellen Instanzen und Stoffen nicht einmal als solches mehr wahrnehmen. Und während die Online-Kommunikation und -Identitäten durchgeschüttelt werden, entstehen große Fragezeichen hinter gleich ganzen Wirtschaftszweigen: Denken wir nur einmal kurz an die neuen Herausforderungen der Werbeindustrie, die plötzlich den auftraggebenden Unternehmen beweisen muss, dass ihre Ad-Konsumenten tatsächlich über menschliches DNS-Profil verfügen. Vor wenigen Jahren amüsierten uns die bizarren, selbstgesteuerten Dialoge zwischen Voice-Assistenten verschiedener Hersteller. Künftig könnte Kommunikation unter Maschinen zur Norm werden.
Okay. Wir stehen also an einem Scheideweg. Doch wie gehen wir von hieran weiter? Aus dem Kopf fallen mir drei Möglichkeiten ein, wie KI-gestützte Kommunikation halbwegs schadlos in die Online-Kommunikation integriert werden kann. Dabei handelt es sich um die Zertifizierung, Identifizierung oder Verifizierung. Gehen wir die Liste einmal durch…
Zertifizierung
Brüssel hat im Digitalen ja die pfiffigsten Ideen. Und so beinhaltet die erste Version der EU-Regelungen für KI-Nutzung, die noch in diesem Jahr erscheinen sollen, den Vorschlag einer Kennzeichnungspflicht für künstlich erschaffene Inhalte, seien es Texte, Bild- oder Tonformate. In weitergehenden Forderungen kämen auch Zertifizierungspflichten für KI-Dienste in Betracht. Um Grunde geht es darum, dass derartiger Content voraussetzend mit Signaturen versehen werden muss, die diesen eindeutig als nicht-menschlich deklarieren. Doch wie soll das in der Praxis funktionieren – und vor allem, wie soll das kontrolliert werden? Müssen GPT-Texte künftig mit einem Sonder-Emoji versehen werden, das von der Erzeugung bis zur Veröffentlichung mitgeschleift werden muss?
Die Idee der Kennzeichnung ist nicht neu. Es gibt durchaus zaghafte Versuche, KI-Content als solchen identifizierbar zu machen. So hat sich etwa Adobe dazu entschlossen, zumindest in der Beta-Phase des Firefly-Bildgenerators künstlich generierte Grafiken durch eine Art sichtbares Wasserzeichen und einen unsichtbaren kleinen Hinweis in den Metadaten der Dateien zu markieren. Beides lässt sich jedoch schon jetzt schneller entfernen, als es für einen Schluck Kaffee braucht. Kurzum: Ich sehe nicht, wie eine Kennzeichnungspflicht derzeit funktionieren, geschweige denn durchgesetzt werden soll.
Identifizierung
Folgen wir an dieser Stelle dem Gedankenspiel „Feuer mit Feuer bekämpfen“. Wir könnten KI einsetzen, um Spuren künstlicher Intelligenz im Content automatisch zu flaggen. Ein Schnüffel-Algorithmus rattert dabei über Texte, Bilder und Videos, um auffällige Posts zu identifizieren und entsprechend auszuweisen und menschlichen Nutzern eine Orientierung zu geben. Doch wie gut sind KI-Analyzer eigentlich heute? Ich habe kürzlich einen kleinen Test dazu gestartet und gelernt, dass es sich bei dem deutschen Grundgesetz von 1949 mitnichten um eine Niederschrift Adenauers, Heuss‘, Schumachers und des Parlamentarischen Rats handelt. Sondern um ein künstlich generiertes Paragrafen-Essay – um einen plumpen Versuch arbeitsscheuer Gründerväter, die mit diesem Test, Gottseidank!, aufgeflogen sind.
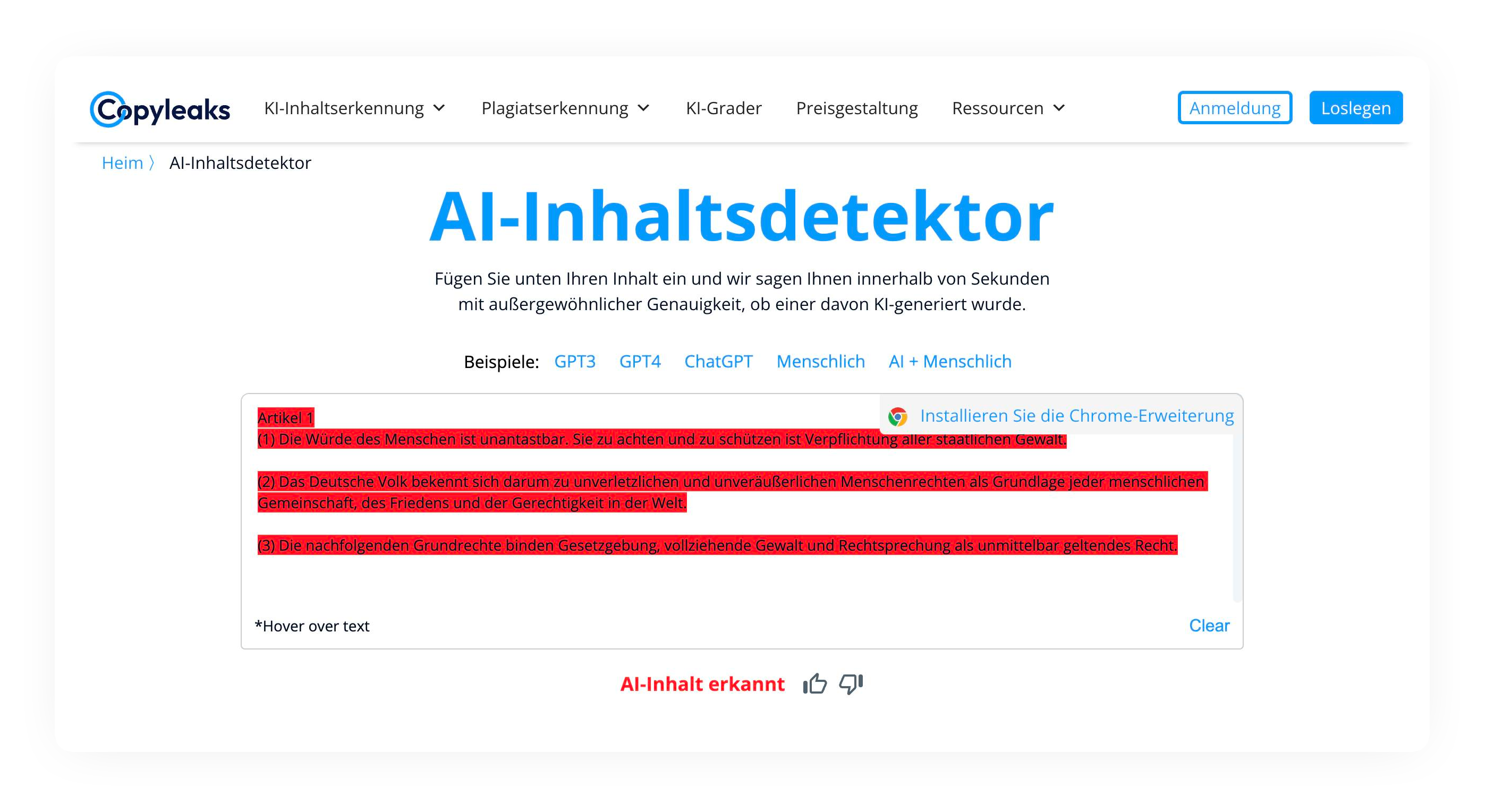
KI-Analyzer sind nicht sonderlich zuverlässig, zudem birgt ein solcher Kontrollmechanismus die Unsicherheit falschpositiver Ergebnisse. Im Grunde drohen hier dieselben Gefahren, wie wir sie schon aus der Urheberrechtsdebatte und dem Wahnsinn der Uploadfilter kennen. Ein zweites Gegenargument besteht aus den Kosten: Es handelt sich bei der Kontrolle nicht um einen simplen Signaturenabgleich mit der Datenbank. Die KI muss richtig anpacken – rechnen, analysieren – um Inhalte halbwegs korrekt einzuschätzen. OpenAI, die Macher von Chat GPT zahlen täglich rund 700.000 US-Dollar für den Betrieb des Sprachmodells. Es spricht einiges dafür, das eine KI, die dessen Content sorgsam rezipiert und analysiert, nicht weniger ressourcenhungrig ist.
Verifizierung
Wir können das Ganze auch ex negativo betrachten: von der Perspektive der Nutzer aus. Damit wäre nicht die Maschine den Netzwerken Rechenschaft schuldig, sondern der Mensch. Sie müssten den Nachweis ihrer Identität erbringen, sich als Individuum mit eindeutigen Daten verifizieren lassen. Dieser Vorstoß schlüge in dieselbe Kerbe, die Elon Musk für sein Twitter-Höllenloch bereits bearbeitet hat und folgt der simplen Idee: Bots sind ein Problem und die bezahlte Verifizierung ist die beste Lösung. Ob kostenlos oder kostenpflichtig sei einmal dahingestellt, doch eine solche Einzelakkreditierung birgt ganz neue Risiken, denn sie geht mit einem gigantischen Reichtum an persönlichen Daten einher. Der Coming-Out-Teenager wird dabei genauso metrisch erfasst, wie die alleinerziehende Mutter, die sich mit frischer Krebsdiagnose hilfesuchend an die Community wendet.
Starting April 15th, only verified accounts will be eligible to be in For You recommendations.
The is the only realistic way to address advanced AI bot swarms taking over. It is otherwise a hopeless losing battle.
Voting in polls will require verification for same reason.
— Elon Musk (@elonmusk) March 27, 2023
Zum einen können diese Daten abhandenkommen oder missbraucht werden, was angesichts der bisherigen Bilanz sozialer Netzwerke weniger eine abstrakte Gefahr als eine unausweichliche Wahrscheinlichkeit darstellt. Zum anderen ist die zwingende Offenlegung von Identitäten eine Maßnahme, die weit über die einfache Klarnamenpflicht hinausgeht, und somit eine akute Gefahr für Personen, die dringenden Schutz vor staatlicher Verfolgung bedürfen. Iranische Dissidenten oder mutige Oppositionelle in Moskau sind damit vor Behörden nicht länger sicher, die sich schon heute etwa bei Twitter mit einem simplen Fingerschnippen Einblick in die Nutzerdaten geben lassen.
Und nun?
Man sieht: Die künstliche Intelligenz hat in den letzten Jahren erhebliche Fortschritte bei der Nachahmung menschlicher Sprache und der Erstellung von Texten und Bildern gemacht. Sie wird zunehmend in sozialen Medien, Online-Marketing und anderen Bereichen eingesetzt. Die Grenze zwischen menschlichem und maschinell erstelltem Inhalt verschwimmt immer mehr, was Herausforderungen für die Authentizität und die Zuverlässigkeit von Informationen mit sich bringt. Es ist wichtig, dass die Ethik und die gesetzlichen Rahmenbedingungen für den Einsatz künstlicher Intelligenz in diesen Bereichen sorgfältig geprüft und gestaltet werden, um sicherzustellen, dass sie zum Wohle aller genutzt wird.
(Fazit verfasst von Chat GPT / featured Image KI-generiert)